
When data is read from a file or network it is read byte by byte into a data buffer.
Data Buffers are temporary storage used for transferring data.
To work with binary data we will need access to these buffers.
To work with buffers in nodejs and node-red we use the buffer object.
The following screen shot of the node command line shows how we work with characters using the buffer object.
The first thing we need to do is create a buffer. This can be done in a number of ways:
Create a buffer from a string.
Buffer.from('abcde')

Create a buffer from an array of numbers
var b = Buffer.from([1,2,3,4]);

Notice the difference between numbers and strings and numbers as numbers.

Create an empty buffer of 10 bytes and Initialise it.
var b = Buffer.alloc(10);

Working With String Buffers
If you read the tutorial on data and character encoding you will see that Characters and numbers e.g A and 1 are represented as bytes by encoding them.
In the early days of computing ASCII was the encoding standard,and was very simple as a character was a byte.
However due to the lack of support for foreign characters ASCII has been replaced by utf-8.
Below is a screen shot showing a partial ASCII table for the numbers 0-9.
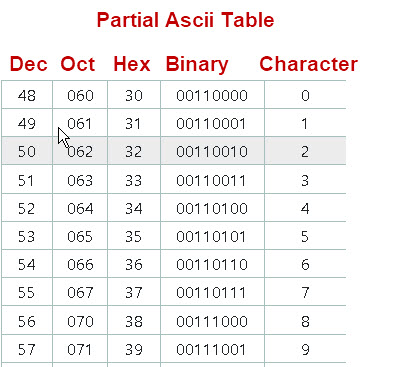
1 is encoded as hex 31 and binary 00110001
When we use the Buffer.from method to create a buffer from a string then we can also specify an encoding scheme, utf-8 is the default.
Now utf-8 uses 1 to 4 bytes to encode an character whereas ASCII only uses 1 byte.
However when we encode the characters ‘abcde’ we only have 5 bytes.
This is because the English characters are the same in ASCII as in utf-8.
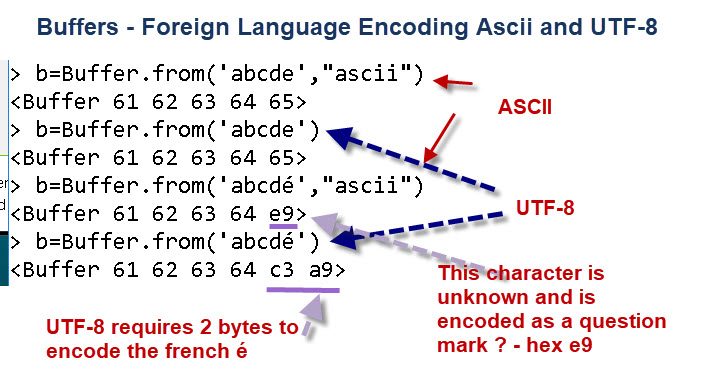
However what happens if we encode foreign language characters like the French é ?
In the above screen below we see for English characters the encoding is the same in ASCII as UTF-8 and uses a single byte.
However when encoding the French é UTF-8 uses 2 bytes and ASCII can’t encode it and so it substitutes the question mark character.
Interpreting Data in Buffers
When reading in data from the network or from a file it is important to know what type of data we are working with.
If it is string data then what is the encoding that was used. If we take our simple string example of abcdé encoded as UTF-8.
If we read it using the toString() method, and decode it as ASCII this is what we get:

You will notice that ASCII uses 1 byte per character the French character é is encoded as C3 A9.
It is decoded incorrectly in ASCII as C).
Node-Red Example Reading a File
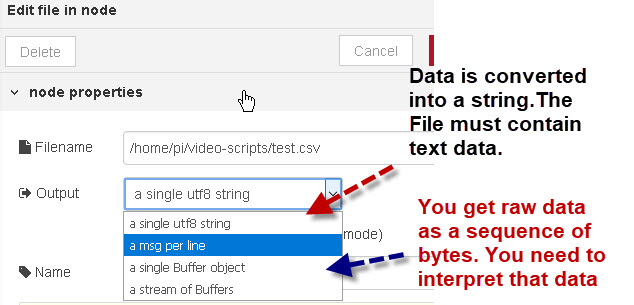
If you look at the file read node you will see that there are 4 options of how the read presents the data to your flow. They are:
- A single utf-8 string – In the case the entire file is read and presented to your program as a text string. You need to wait for the read to complete before you can process the data.
- One msg per line– Presents the data to your program as lines of text. You can process data while still reading the file.
- A single Buffer object – Same as the first option but now you have a sequence of raw bytes. You need to wait for the read to complete before you can process the data.
- A stream of buffers -Same as second option but you have a sequence of bytes so you can process data while still reading the file.
The first and second options are the most common as files normally contain text data.
If the data in the file isn’t text data or not encoded as utf8 then the single utf8 and 1 msg per line options won’t work as with these options the data is read in, and decoded using utf8 into characters.
Note: See data encoding tutorial for more details
The third and forth options are for when the file contains binary data or text data encoded in another format other than utf8 or ASCII..
These options reads the data into you script/flow without any interpretation i.e as raw data.
Video
In the video below I cover the above and also show you how to use Buffers in node-red to read text data from a file.
Demo flow used in video

Encoding and Decoding Integers and Floats
When working with machines you will often be required to encode and decode integer and float data, modbus is a good example.
Early computers used 16 bits to represent an Integer and 32 bits for a floating point number.
Today they can be much larger but the process is the same.
The image below shows a 16 bit Integer and how it is organised into bytes:

It is important to understand that because data is sent across a network in bytes it is important to understand whether the MSB (Most Significant Byte) or the LSB (Least Significant Byte) is transmitted first.
This is know as endianness and is discussed in the video.
Most networks use Big endianness (MSB first).
Video -Node-Red Buffers- (Integers and Floats)
Demo flow used in video
Worked Examples:
Creating a 2 byte buffer from an Integer (16 bits)
First we create an 2 byte empty buffer and then write the integer into it
var buf=Buffer.alloc(2); buf.writeInt16BE(17201);
Creating a 4 byte buffer from an Integer (32 bits)
First we create an 4 byte empty buffer and then write the integer into it
var buf=Buffer.alloc(4); buf.writeInt32BE(17201);
Creating a 16 bit Integer from a 2 byte buffer
We start with our 2 byte buffer containing a 16 bit integer and then we create the integer using the read method.
var buf=Buffer.from([0x43,0x6c]) var res =buf.readInt16BE()
Creating a 4 byte buffer from an Float (32 bits)
First we create an 4 byte empty buffer and then write the Float into it
var buf=Buffer.alloc(4); buf.writeFloatBE(131.3)
Creating a 32 bit Float from a 4 byte buffer
We start with our 4 byte buffer containing a 32 bit Float and then we create the float using the read method.
var buf=Buffer.from([0x43,0x03,0x4c,0xcd]) var res =buf.readFloatBE();
Related Tutorials and Resources
- w3schools Buffer Object
- How to Use Node-Red with Modbus
- Working with JSON data in Node-red
- Using the Node-Red Function Node- Beginners Guide
- Storing Data in Node-Red Variables
Thank you for your clarification!